In Madisoft si fa largo uso di funzioni Lambda ed a volte si incappa in errori, alcuni dei quali però non così importanti da essere trattati con un’eccezione software. Per questo un costante monitoraggio è essenziale per risolvere, in maniera repentina, eventuali errori fatali ed allo stesso tempo c’è bisogno di un sistema che ci notifichi i “soft fail”, ovvero quei fallimenti nell’esecuzione non essenziali al fine dell’obbiettivo principale.
La via per effettuare queste operazioni non è sicuramente scorrendo a mano un CloudWatch LogGroup, ricercando tramite filtri e pattern correlati. Una delle soluzioni da noi ideata è quella di monitorare ad intervalli regolari un LogGroup tramite CloudWatch Logs Insights, ed inviare (eventuali) corrispondenze delle query di ricerca in una CloudWatch Custom Metric. Successivamente si vanno a creare allarmi tramite CloudWatch Alarm con le metriche disponibili. Questa non è sicuramente un’idea innovativa ma al momento dell’implementazione non era presente nessuna soluzione “out of the box” che facesse al caso nostro.
Una domanda consona, in questo caso, sarebbe: Perché non utilizzare solo le metriche AWS/Lambda/Errors, disponibili in qualsiasi account AWS (senza costi aggiutivi) e senza alcun bisogno di scrivere codice?
L’utilizzo delle metriche standard è da tenere in considerazione ma non può essere l’unica soluzione, almeno per il nostro scopo. Infatti in questo modo non andremmo a monitorare eventuali errori non bloccanti o warning. Cercando di seguire un pattern fault tolerant development, se si verifica un errore in una parte non critica del codice, ad esempio l’invio di una notifica durante l’esecuzione del flusso della Lambda, l’esecuzione non deve essere interrotta. Sarebbe molto meglio generare un messaggio [ERROR] o [WARN] nei log per ulteriori indagini e continuare l’elaborazione.
Quindi in caso di errori bloccanti le metriche AWS/Lambda/Errors sono la soluzione migliore ma non può essere l’unica.
Goal
Creare una piccola infrastruttura a microservizi che ci consenta di tracciare i “soft fail” all’interno di funzioni Lambda, in modo parallelo ad allarmi basati sulla metrica AWS/Lambda/Errors.
Infrastructure
Design notes
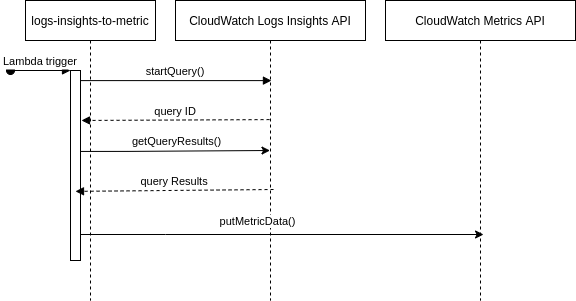
La creazione di una funzione Lambda adatta al nostro scopo non è troppo complessa se si hanno chiari i concetti delle Custom Metrics, ma bisogna prestare attenzione alla natura asincrona di CloudWatch Logs.
In primo luogo, le nuove voci nei log diventano visibili e interrogabili in CloudWatch Logs Insights dopo un certo ritardo, nel nostro caso di circa 3 minuti. Quindi dovremmo interrogare il servizio, tramite startQuery(), nel passato e pubblicare una metrica di conseguenza, ad esempio partendo da 12 ore indietro fino a 3 minuti fa.
Seconda nota, bisogna attendere che la chiamata getQueryResults() termini la sua esecuzione con uno stato: Complete, Failed o Canceled, il quale avviene alcuni secondi dopo l’avvio. Questo stato che ci viene restituito corrisponde a queryResults ed in caso corrisponda a Complete avremo nella risposta il risultato della query.
Implementation
Per l’implementazione della funzione è stata presa ad esempio questa applicazione, sotto licenza MIT, disponibile nel AWS Serverless Application Repository. L’applicazione però non soddisfa interamente le nostre richieste ed inoltre tendiamo ad implementare le nostre funzioni in Python3.6+.
Descrivere nei dettagli ogni singolo servizio dell’infrastruttura sarebbe troppo prolisso e probabilmente non rilevante, al fine di capire come ricrearne una che si adatti alle proprie esigenze. Andremo quindi a spiegare sommariamente i servizi che la compongono e il flow che segue la funzione Lambda durante la sua esecuzione.
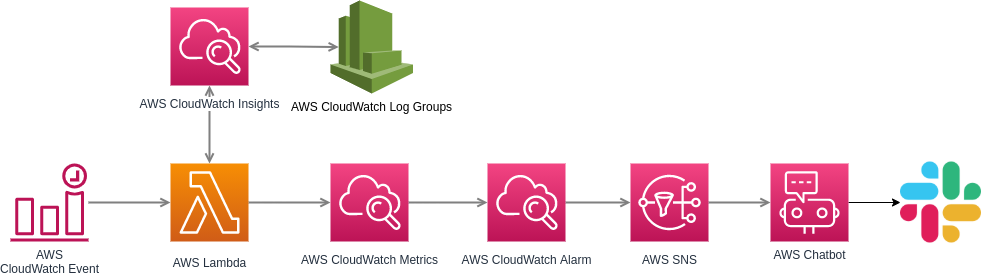
La miccia che mette in moto, in maniera schedulata, tutto il sistema può essere sia CloudWatch Event che Amazon EventBridge. Questo servizio, dunque, esegue il cuore di tutta l’infrastruttura, ovvero la nostra Lambda che si occupa di richiedere l’esecuzione della/delle query a CloudWatch Insights e pubblicare eventuali risultati su CloudWatch Metrics (torneremo successivamente nei dettagli di queste operazioni). A questo punto un allarme di CloudWatch Alarms può leggere (con threshold, period, etc, configurati in base alle proprie preferenze) la metrica custom da noi creata e su cui stiamo pubblicando i risultati delle query. Per terminare, si è andati ad integrate AWS Chatbot per l’invio di notifiche verso Slack. Infatti in caso di allarmi il servizio pubblicherà, sul canale Slack da noi indicato, un messaggio formattato dove ci viene indicato quale metrica è andata in allarme ed il relativo grafico temporale dei dati.
Torniamo quindi alla nostra funzione Lambda. Come descritto in precendenza, viene eseguita tramite un evento CloudWatch/EventBridge, tuttavia è possibile creare multipli eventi in base alle risorse che vorremmo analizzare. Nel caso venga fatto proprio questo, ci saranno tanti eventi quanti le risorse che vogliamo monitorare. Questi eventi processeranno la funzione correlata, passandole l’evento per la sua esecuzione, i quali conterranno una struttura simile alla seguente:
|
1 2 3 4 5 |
{ query_name: "Lambda1234", # Insights query name. query_period: 3600, # The beginning of the time range to query, in minutes. metric_unit: "Count" # Measure unit to use when storing the metric. Details boto3 put_metric_data. } |
Di queste 3 chiavi la prima è sicuramente quella più importante, infatti la prima azione che la nostra Lambda esegue è recuperare la definizione della query tra quelle da noi precedentemente create nel servizio Insights stesso:
|
1 2 3 4 5 6 |
queries = boto3.client('cloudwatch').describe_query_definitions( queryDefinitionNamePrefix=insight_query_name) # Filter the Insights queries (if more with the same NamePrefix) to get only information related to our specific query. query_def = next(filter(lambda x: x.get('name') == insights_query_name, queries.get('queryDefinitions')), None) if not query_def: raise ValueError(f'Query: {insights_query_name}, not found. Please check query name') |
A questo punto possiamo effetturare la richiesta di esecuzione della query e recuperare l’ID nel caso la richiesta sia andata a buon fine (maggiori dettagli qui):
|
1 2 3 4 5 6 |
start_query_response = boto3.client('cloudwatch').start_query( logGroupNames=log_groups, queryString=query_string, startTime=query_start_time, endTime=query_end_time) query_id = start_query_response.get('queryId') |
Avendo l’ID della query effettuata, possiamo recuperarne il risultato (maggiori dettagli qui):
|
1 2 3 4 5 6 |
while response is None or response.get('status') not in ('Complete', 'Failed', 'Cancelled'): time.sleep(1) response = boto3.client('cloudwatch').get_query_results(queryId=kwargs['insights_query_id']) # Extract the results and proceed to the next query if response.get('status') != 'Complete': raise ConnectionError("Query failed") |
Penultimo step, andiamo a creare il nostro payload da inviare a CloudWatch Metrics per la metrica custom. La struttura da inviare varia in base all’ array Dimensions da inviare, quindi la costruzione cambia anche in base ai risultati della query stessa. Lo schema della struttura è reperibile qui, ma si può facilmente ottenere un esempio di costruzione dall’applicazione AWS inizialmente citata e del metodo boto3 che andremo ora a discutere.
Una volta pronto il Payload da inviare, ci basterà inviarlo a CloudWatch. Nel caso la metrica non esista verrà automaticamente creata.
|
1 2 |
# If the specified metric does not exist, CloudWatch creates the metric. response = boto3.client('cloudwatch').put_metric_data(**metric_data_payload) |
Final Comments
Un sistema del genere potrebbe applicarsi non solo relativamente a funzioni Lambda ma può essere esteso a tutti i servizi che collezionano logs su AWS CloudWatch. Infatti, oltre all’individuazione di “soft fails” nelle Lambda, si potrebbe monitorare qualsiasi altro evento particolare, in CloudWatch Logs, che non ha dei riscontri diretti nelle metriche standard di AWS.
I hope to see you again, cheerio!
