Folder structure is an underrated topic, usually until your project grows and starts having hundreds of files. And what if your project is very very big? What if you have thousands of files? In such a project a well organized folder structure is mandatory to achieve a good level of modularity, understandability and maintainability.
In our project Nuvola, we have a codebase with more than 10 thousand of source code files and for us designing and maintaining a well organized folder structure is one of the priorities. However, this aspect is not important only on big projects: the sooner you start the sooner you get the benefits of a codebase that grows in an efficient and ordered way.
In this article I will show the general principles you can use to design a good folder structure and how we applied these principles to Nuvola. The first step is to survey the existing ways for grouping files of a codebase. In the literature, these are the most common approaches:
- Package by type
- Package by feature
- Package by layer
Package by type
Package by type simply means grouping files by their type: if a file is a Controller it goes in the Controller folder, if it is an Entity it goes in the Entity folder and so on. As an example of this approach we can see the src folder for the Symfony demo project:
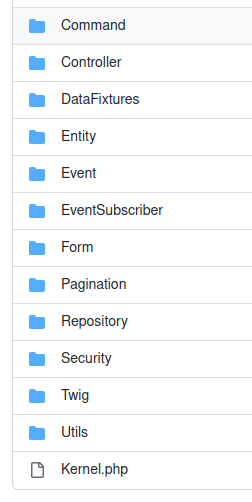
Unfortunately “Package by type” although is the most used approach is also the worst solution for a big project.
Why is it the most used? Since it is the default structure that you have when creating a project with any framework.
Why is it the worst? Since it does not take into account the features of the project. When you add a new feature to your project the files will be placed in many different places. Such related files will be far from each other as you can see here:

In other words, Package by type violates an important principle of software engineering: “low coupling, high cohesion”. In a good codebase, modules should be as independent as possible from other modules (low coupling) while related code should be close to each other (high cohesion). Packaging by type in the primary level of folder structure drastically reduces the cohesion of your software.
Package by feature
Package by feature means that files that belong to the same feature are grouped together. Yes, the definition is very simple yet a question arises: how big should a feature be?
It depends on your project and your taste. It can be as little as a simple scenario like “User Registration” or it can be big like a feature called “User” meaning all the functionalities related to the User like creating, updating, deleting and so on. The size of the feature is something you can decide in your team and can evolve over time. A big feature can be divided into sub-features later on while the project grows up.
We can see a simple package by feature in this example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
src ├── Author │ ├── AuthorController │ ├── AuthorCreated │ ├── AuthorDeleted │ ├── Author │ ├── AuthorRepository │ └── AuthorType ├── Book │ ├── BookController │ ├── BookCreated │ ├── Book │ ├── BookRepository │ └── BookType ├── OtherFeature ├── ... └── Shared ├── AbstractController ├── AbstractType └── ... |
At a glance it is possible to see that this approach maximizes cohesion: all the related files are in the same place. The downside of this approach is that we are mixing together things of different types and with different purposes: this can be solved using a secondary grouping strategy that can be by type or, as we will see later, by layer.
An additional note: when packaging by feature you will find some code that belongs to two or more features. That code should be moved in a shared folder (named “Shared” in these examples).
Package by layer
The goal of this approach is to have the folder structure reflecting the architecture of the project. The fact that it is called “by layer” is just because layered architectures are very common in software development (see The Onion Architecture or The Clean Architecture as an example).
Applying such an approach to a project with a layered architecture simply means creating a folder for each layer and placing the files according to the layer they belong to.
In the following example we will use a very common architecture based on 3 layers: infrastructure, application and domain. Applying “package by layer“ results in something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
src ├── Infrastructure │ ├── AuthorController │ ├── AuthorFormType │ ├── AuthorSQLRepository │ ├── BookController │ ├── BookFormType │ ├── BookSQLRepository │ └── ... ├── Application │ ├── CreateAuthorService │ ├── CreateAuthorDTO │ ├── CreateBookService │ ├── CreateBookDTO │ └── ... └── Domain ├── Author ├── AuthorRepositoryInterface ├── Book ├── BookRepositoryInterface └── ... |
Two important things should be noted from the previous example. First, this approach is a high-level grouping strategy and requires a second level strategy (by type or by feature) or the files in each layer will soon be too many (even in a small project).
Second, with this approach cohesion is reduced with respect to package by feature. However the cohesion reduction is much less than you see at the first sight. In practice, it is very common to design first your domain objects, then work on which part of the domain expose (Application layer) and finally connect those elements with the infrastructure part that handles interactions with clients. In each step, you work almost on a single layer and the involved files are close to each other.
The advantage of this grouping strategy is that it avoids mixing different things together as for each layer, usually, different policies are applied: for example domain objects must be unit tested while a SQL Repository needs integration tests.
Layer separation helps to apply all those policies and also allows to check dependency rules like the one in which infrastructure depends on application, application on domain and never the opposite.
Taking the best
From the analysis done so far it is clear that “package by type” is the worst approach while both “package by feature” and “package by layer” look promising. Package by feature has the problem that it mixes together things that are intrinsically different while package by layer needs a secondary grouping strategy. If we merge these two approaches we solve both problems and we get the best strategy: “package by layer and by feature”.
Wait, how do we merge these two approaches? Do we group first by layer and then by feature? Or should we do the opposite?
Package by Layer/Feature:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
src ├── Infrastructure │ ├── Author │ │ ├── AuthorController │ │ ├── AuthorFormType │ │ └── AuthorSQLRepository │ ├── Book │ │ ├── BookController │ │ ├── BookFormType │ │ └── BookSQLRepository │ ├── ... │ └── Shared ├── Application │ ├── Author │ │ ├── CreateAuthorService │ │ └── CreateAuthorDTO │ ├── Book │ │ ├── CreateBookService │ │ └── CreateBookDTO │ ├── ... │ └── Shared └── Domain ├── Author │ ├── Author │ └── AuthorRepositoryInterface ├── Book │ ├── Book │ └── BookRepositoryInterface ├── ... └── Shared |
Package by Feature/Layer:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
src ├── Author │ ├── Infrastructure │ │ ├── AuthorController │ │ ├── AuthorFormType │ │ └── AuthorSQLRepository │ ├── Application │ │ ├── CreateAuthorService │ │ └── CreateAuthorDTO │ └── Domain │ ├── Author │ └── AuthorRepositoryInterface ├── Book │ ├── Infrastructure │ │ ├── BookController │ │ ├── BookFormType │ │ └── BookSQLRepository │ ├── Application │ │ ├── CreateBookService │ │ └── CreateBookDTO │ └── Domain │ ├── Book │ └── BookRepositoryInterface ├── ... └── Shared ├── Infrastructure ├── Application └── Domain |
The choice is hard since both solutions are very good. To take a decision for our project we surveyed books and articles and found that both strategies are valid but the most common is to apply package by layer first and by feature then. To additionally validate our choice we compared these two approaches in a small part of our project. Also our analysis shows that packaging by Layer/Feature has some slight advantages mainly from a technical point of view:
- Some features exist only at the infrastructure level (think about logging or tracking) and it is a bit awkward to have feature folders containing only the infrastructure folder if you go with Feature/Layer approach
- Mapping folders for framework related configurations is better with Layer/Feature. For example, configuring the directory from which loading entities is more efficient since it is possible to set
src/domain/while with Feature/Layer we should have used the entiresrc/folder - Using tools for dependency tracking, it was easy to define rules like
src/domainshould not depends onsrc/infrastructure
but we were not able to define rules like
src/*/domainshould not depends onsrc/*/infrastructure
Conclusions
Our analysis shows that the strategy Package by Layer/Feature is one of the best solutions. While the project grows, it is important to divide features into sub-features and group features in bigger modules. This process helps to keep the folder structure organized, easily navigable and self-documented, showing the relations among the different features of the project.
Additional resources
Some of the books taken into account during our analysis:
- “Implementing Domain-driven Design” by Vaughn Vernon
- “Advanced Web Application Architecture” by Matthias Noback
The tool used to generate the folder structure diagrams: tree.nathanfriend.io
