Managing complex infrastructures on the cloud can be troublesome as they tend to make use of many different resources and services. To ease the work of creating, deploying and maintaining these infrastructures we always want to use an IaC framework. AWS Cloud Development Kit (AWS CDK) is the standard tool we use to develop new applications on AWS.
One of my first assignments involving the use of CDK was the migration of a simple web application written in PHP from an AWS EC2 instance to a serverless, cloud-base solution based on AWS Fargate. I won’t go into details about the steps to create the needed Docker image from the codebase as I want to focus on the creation of the infrastructure using CDK and on the various constructs and options we used.
The Architecture
Overview
The application had a simplified three-tier architecture where the presentation tier was actually just some HTTP endpoints used to interact with the service. Given that the scope of the application was quite small, we decided to leverage as much as we could the serverless solutions offered by AWS, to help contain costs and, at the same time, minimize the time spent on maintaining the infrastructure.
We decided to deploy the backend of the application as a Service on ECS, using Fargate as a provider. One of the requirements of the task was to try to avoid any unnecessary change to the codebase of the application so we decided to keep a relational DB as the data tier instead of migrating it to a simpler solution like a Dynamodb table. The obvious choice here was Aurora Serverless with MySQL.
To automate the deployments operations (mainly the creation of the Docker image and the update of the ECS Service) we developed a pipeline using CodePipeline, but I won’t detail this part in the article.
The Details
With a clearer idea of the resources we wanted to use we could dive into some details to see what we needed to make them work together.
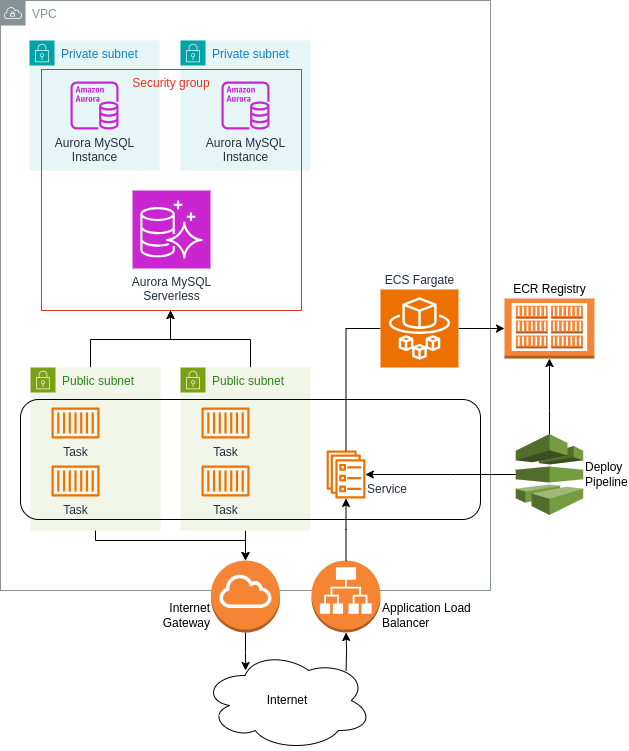
First things first: a new VPC. Most AWS resources need to be deployed inside a VPC. Except in some very rare cases, it’s always a better idea, for security reasons, to isolate each application and service inside its own VPC, even if they are going to integrate with each others. Inside the VPC we wanted to create two different subnets, a private one for the data tier and a public one to allow access to our application from the Internet via HTTP.
The next detail we needed to take into account was about Internet access to and from the backend service. In most cases you don’t want to make your backends directly accessible from the Internet, but you need them to be able to send their responses. This was our case as well, so we decided to use an Application Load Balancer to provide access to the application. To provide Internet connectivity we decided to use an Internet Gateway instead of a NAT, this decision was made mainly because we expected to have a single backend task active most of the time, in this situation a NAT would have cost us more than giving each task a public IP.
The last brick we needed to complete our infrastructure was the ECR repository to store the Docker images of the application.
Final Result
Here the schema of the final architecture we ended up with
The CDK Code
As we can see we had several resources we needed to create and manage, luckily AWS CDK is a big help in situations like this because it offers high level constructs that will create a given set of resources already configured to deploy an application.
I won’t provide all the code used for the infrastructure but I’m just going to highlight some of the constructs and options that helped us to meet all the requirements.
VPC
This part was pretty straightforward, we just had to make sure that the VPC was created without a NAT Gateways, an Internet Gateway was created instead by default.
private = ec2.SubnetConfiguration(
name="private",
subnet_type=ec2.SubnetType.PRIVATE_ISOLATED,
...
)
public = ec2.SubnetConfiguration(
name="public",
subnet_type=ec2.SubnetType.PUBLIC,
...
)
self.my_vpc = ec2.Vpc(self, "vpc",
vpc_name="my-vpc",
max_azs=3,
...
nat_gateways=0,
subnet_configuration=[private, public],
...
)ECR Repository
The ECR repository for the Docker images didn’t have any particular requirements but it’s always a good idea to enable the image scan for security reasons and to limit the number of tags for a given image, especially if the image is automatically generated by a pipeline.
self.my_repo = ecr.Repository(self, "ecr-repo",
repository_name="my-repo",
...
image_scan_on_push=True,
empty_on_delete=False if (config.env == 'prod') else True,
...
)
self.my_repo.add_lifecycle_rule(
description="Life Cycle for " + self.my_repo.repository_name,
max_image_count=10
)Aurora RDS
To create the database we used the standard DatabaseCluster construct but we had to use the specific ClusterInstance.serverless_v2 construct for creating the cluster’s serverless instances.
We also wanted to manage the credentials automatically so that we don’t need to carry out any manual operations for the configuration of a new environment, this was possible using the Credentials.from_generated_secret method.
performance_insights = True if (config.env == 'prod') else False
backup_retention = Duration.days(30) if (config.env == 'prod') else Duration.days(1)
self.my_rds_cluster = rds.DatabaseCluster(self,"rds-cluster",
engine=rds.DatabaseClusterEngine.aurora_mysql(
version=rds.AuroraMysqlEngineVersion.VER_3_04_1),
cluster_identifier="my-rds-cluster",
writer=rds.ClusterInstance.serverless_v2(
"writer",
instance_identifier="my-rds-cluster-writer",
enable_performance_insights=performance_insights,
publicly_accessible=False
),
default_database_name="my-db",
credentials=rds.Credentials.from_generated_secret(
"my-cluster-admin",
secret_name="my-app/db-secret"
),
vpc=self.my_vpc.vpc,
serverless_v2_min_capacity=0.5,
serverless_v2_max_capacity=10,
vpc_subnets=ec2.SubnetSelection(
subnet_type=ec2.SubnetType.PRIVATE_ISOLATED
),
...
)ECS Service
Finally we needed to create the ECS resources for our backends, this is when CDK helped us the most as it provides a whole library called aws_ecs_patterns with a set of handy constructs that could help you bring your application on a standard serverless infrastructure in very few lines of code.
We decided to use the ApplicationLoadBalancedFargateService construct as it was the one that best fitted our needs. As the name suggests the construct provides a quick way to set up a Fargate service on an ECS cluster with an Application Load Balancer in front of it.
The ApplicationLoadBalancedTaskImageOptions is used to configure the task options for the desired services. In our case we used it to configure the PHP application running inside the tasks to connect to the database using the auto generated secret.
Let’s see some code, first we created the cluster and retrieved the database secret
my_cluster = ecs.Cluster(self, "ecs-cluster",
vpc=self.my_vpc.vpc,
cluster_name="my-ecs-cluster"
)
db_secret = ssm.Secret.from_secret_name_v2( self, "db-credentials",
secret_name="my-app/db-secret"
)Then we configured the task we want to run
task_image_options = ecs_patterns.ApplicationLoadBalancedTaskImageOptions(
container_name="my-app-container",
image=ecs.ContainerImage.from_ecr_repository(
self.my_repo.repository,
"latest"
),
secrets={
'DB_NAME': ecs.Secret.from_secrets_manager(
secret=db_secret, field="dbname"
),
'DB_USER': ecs.Secret.from_secrets_manager(
secret=db_secret, field="username"
),
'DB_PASSWORD': ecs.Secret.from_secrets_manager(
secret=db_secret, field="password"
),
'DB_HOST': ecs.Secret.from_secrets_manager(
secret=db_secret, field="host"
),
'DB_PORT': ecs.Secret.from_secrets_manager(
secret=db_secret, field="port"
)
}
)Finally we could create the ECS service
self.my_ecs_service = ecs_patterns.ApplicationLoadBalancedFargateService(self, "my-ecs-service",
cluster=my_cluster,
task_subnets=ec2.SubnetSelection(
subnet_type=ec2.SubnetType.PUBLIC
),
desired_count=1, # You can't set this to 0
task_image_options=task_image_options,
public_load_balancer=True,
assign_public_ip=True, # We needed this to grant Internet connectivity with the Internet Gateway
load_balancer_name="my-app-alb",
service_name="my-ecs-service",
...
)Unfortunately we soon found out that there was a problem with this configuration. The stack creation for the ECS service timed out because it couldn’t find the image for the task and it doesn’t accept a desired_count of 0.
But to create the image we needed the deploy pipeline and to create the pipeline we needed the ECS service already in place for the deployment phase… Kind of a circular dependency!
We tried to solve this problem by digging deeper into the construct’s options but we couldn’t find a working solution. Eventually we worked around the issue by leveraging the ability of CDK to access the lower level construct (the so-called “Cfn” layer) to set the desired_count option to 0. The level 1 layer of CDK is an actual 1 on 1 representation of the resources that will be defined by the CloudFormation stack created by CDK. This allows us to bypass the limitations imposed by the high level constructs.
self.my_ecs_service.service.node.find_child('Service').desired_count = 0We then proceed to create an Autoscaling Group to allow our application to scale in and out based on the CPU utilization.
auto_scaling_group = self.my_ecs_service.service.auto_scale_task_count(
max_capacity=5,
min_capacity=1
)
auto_scaling_group.scale_on_cpu_utilization(
"my-app-asg",
target_utilization_percent=80,
policy_name="my-app-cpu-policy"
...
)And finally we made sure that the tasks running inside the service could access the database tier, this method configured automatically the Security Groups for both resources to allow the connection.
self.my_ecs_service.service.connections.allow_to_default_port(
my_rds_cluster,
"Allow ECS Service - RDS"
)And that’s it!
Conclusions
Overall we were quite satisfied with the result and with the fact that we were able to create a scalable serverless infrastructure with so few lines of code. The high level constructs provided by CDK and their level of abstraction, paired with the ability to access the lower Cfn layer, were quite useful to accomplish most of the tasks needed and to configure the infrastructure to our needs.
